| title: | Monitoring |
|---|---|
| Author: | Lars, vm069 |
| description: | Hackspace Rostock e.V. Monitoring Workshop |
| css: | workshop_style.css |
Themen
- Wen, wie und warum überwachen?
- Beobachten
- Überwachen
- Eingreifen
- Praxis!
Warum wollen wir überwachen?
- Auslastung und Nutzungsmuster analysieren
- Auswirkungen von Änderungen erkennen
- Ausfälle erkennen und nachvollziehen
- Ausfallzeiten minimieren
- Seiteneffekte erkennen
Wen wollen wir überwachen?
- Dienste stehen im Fokus
- diese benötigen:
- Verkehrsträger (Router, Switches)
- Ausführende (Server)
- Infrastruktur (Backup)
- externe Dienstleister (z.B. Telefonie-Server, Mail-Server)
Wie wollen wir überwachen
- ohne menschliche Interaktion
- geringe Beeinflussung des Messobjekts
- im Detail (von innen)
- im Überblick (von außen)
Teil I: Beobachten
Ziele:
- Trends erkennen
- Auslastungen abschätzen
- Einfluss von Änderungen prüfen
- Ursachen bei Problemen ermitteln
Teil I: Beobachten
Typische Schritte:
- Daten erfassen
- Daten speichern
- Daten visualisieren
Teil I: Beobachten
Typische Werkzeuge:
- cacti
- collectd
- ganglia
- munin
- ???
Die weitere Diskussion bezieht sich beispielhaft auf munin.
Struktur von munin
Munin-Graphen
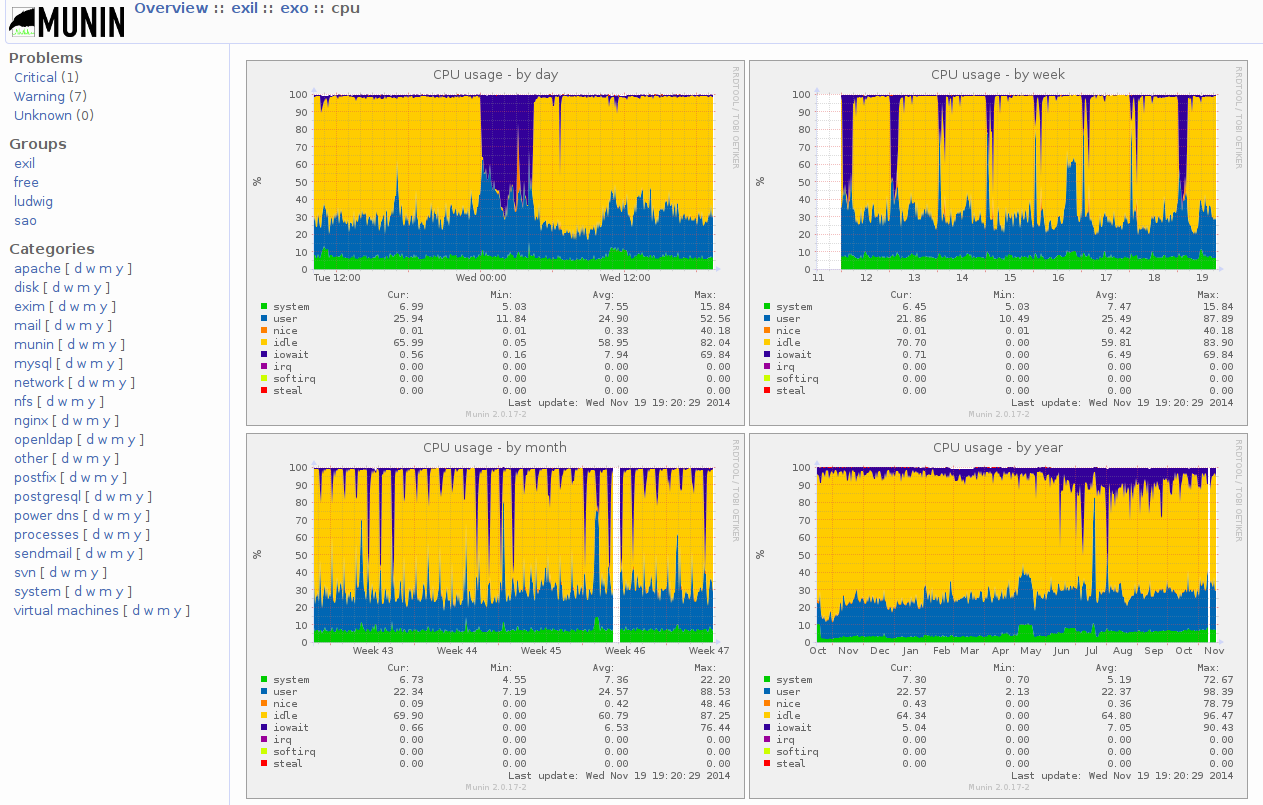
Munin-Graphen
Munin-Graphen
Struktur von munin
- node läuft auf jedem (zu) überwachenden System
- master sammelt von alle Nodes regelmäßig aktuelle Zustandsinformationen
- Webserver auf master liefert Visualisierung aus (on-demand oder periodisch erzeugt)
Plugins
- sehr einfache Programme in beliebiger Sprache
- viele Plugins werden mitgeliefert
- viele verfügbare Plugins: http://gallery.munin-monitoring.org/
- Selberschreiben macht Spaß!
Plugins - Ergebnisse
Sehr einfache Struktur:
root@cerebrum:~# munin-run load load.value 1.90
Plugins - Struktur
root@cerebrum:~# munin-run load config graph_title Load average graph_args --base 1000 -l 0 graph_vlabel load graph_scale no graph_category system load.label load graph_info The load average of the machine describes how many processes are in the run-queue (scheduled to run "immediately"). load.info 5 minute load average
munin: triviales Beispiel
#!/bin/sh
ACCESS_LOG_DIR=/var/log/apache
ACCESS_LOG_FILE="$ACCESS_LOG_DIR/$(ls -tr "$ACCESS_LOG_DIR" | grep access-.*.log | tail -1)"
if [ "$1" = "config" ]; then
echo 'graph_title Pound proxy requests'
echo 'graph_args -l 0'
echo 'graph_vlabel Number of requests'
echo 'graph_category system'
echo 'graph_scale no'
echo 'access.label requests'
echo 'access.min 0'
echo 'access.type DERIVE'
exit 0
fi
echo -n "access.value "
wc -l < "$ACCESS_LOG_FILE"munin: lokal in Nutzung
#!/bin/sh
INTERFACE=br-lan
[ "$1" = "autoconf" ] && echo yes && exit 0
if [ "$1" = "config" ]; then
echo 'graph_title Binaere Mitbewohner'
echo 'graph_args -l 0 -u 15'
echo 'graph_scale no'
echo 'graph_category menschen'
echo 'clients.label ARP-Eintraege'
echo 'clients.draw AREA'
exit 0
fi
echo "clients.value $(expr $(arp | grep "$INTERFACE$" | wc -l))"munin: sehr spezifisch
#!/bin/sh
DRUPAL_DB_PREFIX=drupal_
get_drupal_databases() {
mysql --batch -e "show databases" | grep "^$DRUPAL_DB_PREFIX"
}
if [ "$1" = "config" ]; then
echo 'graph_title Number of drupal accounts'
echo 'graph_args -l 0'
echo 'graph_vlabel Number of drupal accounts'
echo 'graph_category system'
echo 'graph_scale no'
get_drupal_databases | while read dbname; do
echo "users_$dbname.label ${dbname#$DRUPAL_DB_PREFIX}"
echo 'users_$dbname.max 10000'
echo 'users_$dbname.min 0'
echo 'users_$dbname.type GAUGE'
done
exit 0
fi
# output the number of users
get_drupal_databases | while read dbname; do
echo -n "users_${dbname}.value "
mysql --batch "$dbname" -e "select count(*) from users" | grep -E "^[0-9]+$"
doneInstallationsvorgang
- Pakete munin und munin-node installieren
- bei munin-node konfigurieren, welche IPs zugreifen dürfen
- Auslieferung der Visualisierung via Webserver
- (optional) on-demand-Erzeugung von Graphen
- (optional) rrdcached installieren
Schönheit von munin
- node braucht nur geringe Ressourcen (z.B. einfache openwrt-Router)
- hübsche Graphen
- wunderbar einfaches Plugin-System
Nachteile von munin
- offener Port auf überwachten Systemen
- alternativ: ssh-Transport
- IO- und Ressourcen-intensiv für viele Nodes
- rrdcached reduziert Lesen und Schreiben
- on-demand-Erzeugung für geringe CPU-Last
Teil II: Überwachen
Mission: nicht nur Zahlenwerte erfassen, sondern gut von böse unterscheiden.
Teil II: Überwachen
Ziele:
- Verkürzung von Ausfallzeiten
- Erkennen von Nebeneffekten
- (Dokumentation)
Teil II: Überwachen
Typische Werkzeuge:
- nagios/icinga/shinken-Familie
- xymon
- zabbix
- zenoss
- ???
Die weiteren Ausführungen beziehen sich auf die nagios-Familie.
Teil II: Überwachen
Typischer Ablauf:
- regelmäßig Tests ausführen
- Ergebnisse:
- Zustand (OK/Warning/Error)
- (optional) Performance (z.B. Ping-Latenz)
- bei Fehlschlag: den Prüfzyklus anpassen (je nach Konfiguration)
- bei Fehlschlag über Toleranz: Aktionen ausführen (z.B. Mailversand)
nagios-Familie
- Konfigurationen und Tests sind überwiegend kompatibel
- nagios: das Original
- icinga: der community-Fork
- shinken: Rewrite in Python
Objekte der Überwachung
- Hosts
- Dienste
Abhängigkeiten
- Minimierung unnötiger Tests bei Ausfällen
- bei icinga und shinken umgesetzt
Verteilte Prüfung
- warum?
- verschiedene Sichten
- Redundanz
- (Lastverteilung?)
- wie?
- shinken: wird direkt unterstützt
- icinga: unklar
- nagios: unklar
Plugins
- einfache Programme in beliebiger Sprache
- Ausgabebeispiele:
OK - fresh timestamp | 1731s WARNING - slightly outdated timestamp | 189600s CRITICAL - outdated timestamp | 84374579s
Plugin-Beispiel
#!/bin/sh
SSH_CONNECTION="$1"
FILENAME="$2"
WARN_AGE="$3"
CRITICAL_AGE="$4"
# der Dateiname kann auch globs beinhalten (*)
FILE_TIMESTAMP=$(ssh "$SSH_CONNECTION" "sh -c \"stat -c '%Y' \"$FILENAME\"\"" | sort -n | tail -1)
# remote time
NOW="$(ssh "$SSH_CONNECTION" "date +%s")"
AGE="$((NOW - FILE_TIMESTAMP))"
test "$AGE" -le "$WARN_AGE" && echo "OK - fresh timestamp | ${AGE}s" && exit 0
# warning?
test "$AGE" -le "$CRITICAL_AGE" && echo "WARNING - slightly outdated timestamp | ${AGE}s" && exit 1
# critical?
echo "CRITICAL - outdated timestamp | ${AGE}s" && exit 2Entfernte Tests
- nrpe-Plugins
Benachrichtigungen
- Häufigkeit
- Zeitfenster
- Werkzeug (Mail, Jabber, ...)
Schönheit
- einfache Plugins
- reichhaltige Plugin-Vielfalt
Unschönes
- keine meta-template-Fähigkeit für wiederholende Teststrukturen
Abgrenzung Beobachten / Überwachen
- primäres Ziel: Aufzeichnung / Benachrichtigung
- munin kann auch benachrichtigen
- nagios/... kann auch aufzeichnen
| data-x: | 0 |
|---|---|
| data-y: | 1000 |
| data-z: | 0 |
| data-rotate: | 180 |
| data-rotate-z: | 20 |
| data-rotate-x: | 90 |
| data-rotate-y: | 40 |
(S)imple (N)etwork (M)anagement (P)rotocol
- Protokoll zur verwaltung von Netzwerfaehigen Geraeten
- 3 Modi SNMP[1,2c,3]
- klassisches Monitoring Werkzeug
Unterschiede 1,2c vs 3
- SNMP 1 & 2 arbeiten mit "communitystrings" fuer Abfragen
- snmpwalk -v 2c -c community host system
- snmpget -v 2c -c community host sysUpTime.0
- SNMP 3 kennt Nutzer und ist auch in der lage Abfragen verschluesselt auszufuehren
- snmpwalk -v 3 -a MD5 -A password -l authNoPriv -u user host system
- snmpget -v 3 -a MD5 -A password -l authNoPriv -u user host system.sysUpTime.0
- DISMAN-EVENT-MIB::sysUpTimeInstance = Timeticks: (627727) 1:44:37.27
MIB & OID's
- MIB = Management Information Base
- entweder durch Nummern oder alternativ durch alphanumerische Bezeichnungen (z.b. system == 1.3.6.1.2.1.1)
- sind in RFC's definiert
- OID = Object Identifier
- sind die numerische Darstellung der MIB's (z.b.:1.3.6.1.2.1.1.5==sysUpTime)
- Vorfuehrung folgt.
SNMP-Traps
- SNMP Nachrichten die ohne aktive Abfrage gesandt werden (z.B. von Druckern, Routern, ...)
- Benachrichtigung ueber zu hohe Temperatur im Gehaeuse oder geringen Tonerstand
- koennen mit spezifischen Deamon aufgenommen werden
- aehnlich zu syslog jedoch mit genauer (numerischer) Beschreibung des Ereignisses
Eingreifen
- Erkennung fehlerhafter Zustände
- Auslösen einer definierten Aktion
Beispiele - Monit
check process olsrd with pidfile "/var/run/olsrd.pid" start program = "/etc/init.d/olsrd start" stop program = "/etc/init.d/olsrd stop"
Beispiele - Monit
check device root-fs with path / if space usage > 75% for 5 times within 15 cycles then alert
Fazit
- relevant für erwartungsgemäß auftretende Fehler
- Korrektur muss gut bekannt sein